
Page All: Viewing All Pages
Page 1
Intro:
A Central Processing Unit is one of the major components of a computer. The CPU controls logic flow and other control type operations. There are many different things inside a modern CPU. How it works is what we are after today.
Assumptions:

I will be referring to a RISC style architecture throughout this article and there are five basic steps in the architecture; Instruction Fetch, Instruction Decode (Register Fetching), ALU/Execution, Memory (Read & Write), Write-back (Register Write). RISC stands for Reduced Instruction Set Computer, basically it means that every piece of data that the CPU wants to operate on needs to be in the register file. If you need to work with data that is in 0xFF56, you need to load it into a register and then work with it. It is due to this nature that these types of CPUs are called load-store machines. x86 ISA CPUs are CISC (Complex). They can work on memory directly, but their instructions are different lengths and need more logic to do. RISC instructions are all the same size. The RISC instructions and data are all aligned in memory and both take exactly one cycle to fetch each instruction.
This article will not be going into how cache helps alleviate bottleneck problems. I will leave that topic until a later article explains how that works as well as concepts such as virtual memory.
We will measure performance in execution time. Exectime = t x InstrCount x CPI
t=Clock Period
CPI=Cycles per Instruction
Commonly, you will see that people refer to IPC which is Instructions per Cycle in the case of super scalar CPUs where in a single-cycle, more than one instruction can complete. In this case Exectime = t x InstrCount x (1/IPC) .
Simple Case - Single-Cycle CPU:
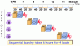
The simplest CPU is a single-cycle CPU. You feed an instruction in and in one clock cycle, the data is produced. Think of going to the laundromat to get your clothes clean. In a single-cycle CPU, you take over a combination of the washing machine (30 minutes), the dryer (40 minutes) and the folding table (20 minutes). No one can use the washing machine until you have completed your entire task. In a single-cycle CPU, each instruction takes one cycle no matter which instruction is executing. The clock speed is determined by the runtime of the longest instruction. In a single-cycle CPU, logic is easy. There is a purely combinational approach to this type of CPU and there is no need to worry about data dependencies or hazards. Today's single-cycle CPUs are typically called micro controllers. Since a single-cycle CPU effectively locks out the entire datapath of the CPU, it is considered to waste resources. Going back to the example, when you finished your washing machine load and moved onto the dryer, someone else could start using the washing machine right after. This is the same as a multi-cycle CPU or pipelined CPU. Most (if not all) server and desktop CPUs are pipelined including the x86 CPUs. In this example, a person exists the laundromat every 90 minutes (30+40+20), which is the execution time of a single instruction.
The execution time for a single-cycle CPU would be t x InstrCount. CPI is equal to 1. Let's say that a typical benchmark is 1,000,000,000 instructions and the clock speed of this particular type of CPU is 200MHz. This particular CPU would take 5 seconds to execute this benchmark.
Intro:
A Central Processing Unit is one of the major components of a computer. The CPU controls logic flow and other control type operations. There are many different things inside a modern CPU. How it works is what we are after today.
Assumptions:
I will be referring to a RISC style architecture throughout this article and there are five basic steps in the architecture; Instruction Fetch, Instruction Decode (Register Fetching), ALU/Execution, Memory (Read & Write), Write-back (Register Write). RISC stands for Reduced Instruction Set Computer, basically it means that every piece of data that the CPU wants to operate on needs to be in the register file. If you need to work with data that is in 0xFF56, you need to load it into a register and then work with it. It is due to this nature that these types of CPUs are called load-store machines. x86 ISA CPUs are CISC (Complex). They can work on memory directly, but their instructions are different lengths and need more logic to do. RISC instructions are all the same size. The RISC instructions and data are all aligned in memory and both take exactly one cycle to fetch each instruction.
This article will not be going into how cache helps alleviate bottleneck problems. I will leave that topic until a later article explains how that works as well as concepts such as virtual memory.
We will measure performance in execution time. Exectime = t x InstrCount x CPI
t=Clock Period
CPI=Cycles per Instruction
Commonly, you will see that people refer to IPC which is Instructions per Cycle in the case of super scalar CPUs where in a single-cycle, more than one instruction can complete. In this case Exectime = t x InstrCount x (1/IPC) .
Simple Case - Single-Cycle CPU:
The simplest CPU is a single-cycle CPU. You feed an instruction in and in one clock cycle, the data is produced. Think of going to the laundromat to get your clothes clean. In a single-cycle CPU, you take over a combination of the washing machine (30 minutes), the dryer (40 minutes) and the folding table (20 minutes). No one can use the washing machine until you have completed your entire task. In a single-cycle CPU, each instruction takes one cycle no matter which instruction is executing. The clock speed is determined by the runtime of the longest instruction. In a single-cycle CPU, logic is easy. There is a purely combinational approach to this type of CPU and there is no need to worry about data dependencies or hazards. Today's single-cycle CPUs are typically called micro controllers. Since a single-cycle CPU effectively locks out the entire datapath of the CPU, it is considered to waste resources. Going back to the example, when you finished your washing machine load and moved onto the dryer, someone else could start using the washing machine right after. This is the same as a multi-cycle CPU or pipelined CPU. Most (if not all) server and desktop CPUs are pipelined including the x86 CPUs. In this example, a person exists the laundromat every 90 minutes (30+40+20), which is the execution time of a single instruction.
The execution time for a single-cycle CPU would be t x InstrCount. CPI is equal to 1. Let's say that a typical benchmark is 1,000,000,000 instructions and the clock speed of this particular type of CPU is 200MHz. This particular CPU would take 5 seconds to execute this benchmark.
Page 2
More Difficult Case - Multi-cycle (Pipelined) CPU:
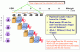
It is easy to see why a single-cycle CPU is considered to be a waste of resources. Remember back to the example of the laundromat. You start washing your clothes and stop everyone else from using the facility until you have left the building. The obvious way to increase throughput is to pipeline the datapath. In this example, we have a three stage pipeline. The washing machine, the dryer, and the ironing board. When you (Person A) are finished with the washing machine, someone else (Person B) starts to use the washing machine. When you are finished drying your clothes, Person B starts using the dryer. A third person (C) starts using the washing machine. In a multi-cycle CPU, the clock speed is set for the longest amount of time one stage of the pipeline takes. In the laundromat example, it would set at 40 minutes since that is the longest stage in the datapath. Since each stage is 40 minutes, there is a person leaving the store every 40 minutes instead of 90! The first person (or instruction) always takes as many clock cycles as there are stages since it is the first instruction to fill the pipe. Pipelining is more complex and requires the addition of invisible pipeline registers between the stages to hold the data.
The execution time for a multi-cycle CPU would be t x InstrCount x CPI. Since we are assuming that we run the same benchmark, there are 1,000,000,000 instructions. We have a 5 stage pipeline and in doing so we increased the clock rate to 500MHz. The CPI we will assume to be 1 after infinity instructions (since the first instruction takes 5 cycles and every other instruction takes 1 after that). There are no stalls or hazards in this CPU. The benchmark would complete in 2 seconds. A major improvement over the single-cycle CPU. This is not exactly what happens in the real world.

Pipelined CPUs open up more problems when there are dependencies and hazards. Back to the laundromat example, if Person A was in the pipeline and is at the folding stage and then realizes that he forgot to wash a few pieces of clothes, the entire pipeline must effectively wait one cycle while Person A does the entire process all over again. How about if Person B could not complete her wash cycle until Person A has finished his folding cycle. There is a waste of 2 cycles in this situation (we are not assuming that the laundromat has forwarding). For 10 people in the best case scenario, the first person exits after 120 minutes then the second after 160 minutes, then the third after 200 minutes, then 240, then 280, 320... You get the idea. Every 4th person has this dependency and requires to do two stages over again. Now the first person exits at 120 minutes, the second at 160, the third at 200, the fourth at 320! This stall now keeps happening and the throughput is lower.
For the case of the 5 stage real CPU, we can assume that the CPI is now 1.6 because of stalls due to dependences. Exectime = t x InstrCount x CPI. The CPU still runs at 500MHz so the Execution time is now 3.2 seconds to complete the benchmark.
How does this type of dependency happen in real CPUs? Look at the two instructions below (I'm dumbing down MIPS ISA).
In the above example, the load instruction reads memory address 0x65FF and stores the contents in register R1. The add instruction adds R6 and R1 and stores the result in register R4. There is a clear dependence of data, R1. If we look at the 5 stage pipeline we see that R1 is not ready until after the Memory stage of the load instruction is completed.

It is true that the CPU could just stall for three cycles until the data is written back to the register file. Three cycles? Yes, in the assumptions above, the CPU gets the register information in the instruction decode stage of the pipeline. How about these two instructions.
The second add instruction needs the result of the first to complete its execution. It would also need to stall three cycles. Surely there must be a better way than this.
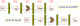
There is, the solution is called forwarding. Also, the decode and write-back stage are half cycles and are split in one cycle allowing the register to be read then written to in one cycle concurrently. This takes care of one stalled cycle. In the case of forwarding and the load-add example, there would be a single-cycle stall and then the data would be forwarded to the execution unit and the CPU would keep churning.
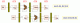
The add-add instruction would not need to stall at all since the CPU handles the forwarding itself.
For the enhancements that were introduced to the CPU, the CPI has been reduced to 1.2. The execution time is now 2.4. Again, there is more to worry about than just dependencies. What about branches and jumps?
This if statement above is a typical example of a branch. Other examples include do while loops, for loops, while loops and any type of goto or jump statement. The last two are known as unconditional branches since they always branch. As you can tell, there are many branches in a type program.
Now we have to see how these instructions are being feed into the CPU to understand why branches are a problem. In a typical RISC system, the instruction and data memory are kept separate so there is no structural hazard (In the IF or MEM stage). The instructions are then feed into the CPU in serial order... For example:
Each instruction begins executing as soon as it can. This means that instructions 1 - 5 will start executing immediately. Instruction 6 must wait until the branch is resolved before it can execute. Let's take a more specific example:
In the above example, the add instruction cannot begin executing until the branch has been resolved. If the CPU were to start executing the add instruction and the branch was taken, the store instruction would be storing the wrong result! It is for this reason that the CPU must stall until the branch can be resolved. After the branch is resolved and the program counter is updated, the CPU will resume as normal. The CPU has no prediction for branches and must effectively flush the pipeline. In this case, the CPU can resolve the branch at the end of the ID stage and update the program counter as well. In this case, there are two stalls for each branch.
Now that we added the problem of branches to the equation, the CPI of the CPU is now 1.4. This means that the execution time of our standard benchmark is now at 2.8 seconds. What can be done to improve this? Predict which way a branch will be taken.
If the CPU predicts that all branches will not be taken, then it can go ahead and start executing the instruction just after the branch without worrying what the branch is. Once the CPU resolves the branch, it can either flush the pipe, or continue to execute the instruction. We are no worse off using this prediction and if branches are not taken, we are better off. I have grossly oversimplified this, but this is how it works.
Now the CPI of our CPU is at 1.3 and the benchmark finishes in 2.6 seconds. For the purpose of this article, this is the best this CPU can hope to achieve.
Conclusion:
Let's compare what we have seen. The single-cycle CPU finishes the benchmark in 5 seconds and is running at 200MHz. The multi-cycle CPU finishes the same benchmark in 2.6 seconds and is running at 500MHz, 2.5x faster in clock speed, but only about 1.92x faster in actual execution time. The modern CPUs all follow this trend and the Pentium 4 line is a great example of this. Intel has increased the pipeline deeper and deeper to increase clockspeeds, but the performance has not increased at the same rate as clockspeed. AMD focuses on doing more per clock (IPC) which is why their pipeline is shorter, but the CPU can accomplish more in one clock cycle. Check back in a week or so for more on CPUs including super scalars and a starter on how cache works.
The diagrams presented in this article come from lecture slides for my class which you can find here: http://guinness.cs.stevens-tech.edu/~arz/ The textbook that was used in the class was Computer Organization and Design: The Hardware/Software Interface, Second Edition.
Thanks for reading and by all means, if you spot any errors in this let me know. You can also discuss this in the forums: »http://www.aseforums.com/.
More Difficult Case - Multi-cycle (Pipelined) CPU:
It is easy to see why a single-cycle CPU is considered to be a waste of resources. Remember back to the example of the laundromat. You start washing your clothes and stop everyone else from using the facility until you have left the building. The obvious way to increase throughput is to pipeline the datapath. In this example, we have a three stage pipeline. The washing machine, the dryer, and the ironing board. When you (Person A) are finished with the washing machine, someone else (Person B) starts to use the washing machine. When you are finished drying your clothes, Person B starts using the dryer. A third person (C) starts using the washing machine. In a multi-cycle CPU, the clock speed is set for the longest amount of time one stage of the pipeline takes. In the laundromat example, it would set at 40 minutes since that is the longest stage in the datapath. Since each stage is 40 minutes, there is a person leaving the store every 40 minutes instead of 90! The first person (or instruction) always takes as many clock cycles as there are stages since it is the first instruction to fill the pipe. Pipelining is more complex and requires the addition of invisible pipeline registers between the stages to hold the data.
The execution time for a multi-cycle CPU would be t x InstrCount x CPI. Since we are assuming that we run the same benchmark, there are 1,000,000,000 instructions. We have a 5 stage pipeline and in doing so we increased the clock rate to 500MHz. The CPI we will assume to be 1 after infinity instructions (since the first instruction takes 5 cycles and every other instruction takes 1 after that). There are no stalls or hazards in this CPU. The benchmark would complete in 2 seconds. A major improvement over the single-cycle CPU. This is not exactly what happens in the real world.
Pipelined CPUs open up more problems when there are dependencies and hazards. Back to the laundromat example, if Person A was in the pipeline and is at the folding stage and then realizes that he forgot to wash a few pieces of clothes, the entire pipeline must effectively wait one cycle while Person A does the entire process all over again. How about if Person B could not complete her wash cycle until Person A has finished his folding cycle. There is a waste of 2 cycles in this situation (we are not assuming that the laundromat has forwarding). For 10 people in the best case scenario, the first person exits after 120 minutes then the second after 160 minutes, then the third after 200 minutes, then 240, then 280, 320... You get the idea. Every 4th person has this dependency and requires to do two stages over again. Now the first person exits at 120 minutes, the second at 160, the third at 200, the fourth at 320! This stall now keeps happening and the throughput is lower.
For the case of the 5 stage real CPU, we can assume that the CPI is now 1.6 because of stalls due to dependences. Exectime = t x InstrCount x CPI. The CPU still runs at 500MHz so the Execution time is now 3.2 seconds to complete the benchmark.
How does this type of dependency happen in real CPUs? Look at the two instructions below (I'm dumbing down MIPS ISA).
Code
LOAD R1,0x65FF
ADD R4,R6,R1
ADD R4,R6,R1
In the above example, the load instruction reads memory address 0x65FF and stores the contents in register R1. The add instruction adds R6 and R1 and stores the result in register R4. There is a clear dependence of data, R1. If we look at the 5 stage pipeline we see that R1 is not ready until after the Memory stage of the load instruction is completed.
It is true that the CPU could just stall for three cycles until the data is written back to the register file. Three cycles? Yes, in the assumptions above, the CPU gets the register information in the instruction decode stage of the pipeline. How about these two instructions.
Code
ADD R1,R2,R3
ADD R4,R3,R1
ADD R4,R3,R1
The second add instruction needs the result of the first to complete its execution. It would also need to stall three cycles. Surely there must be a better way than this.
There is, the solution is called forwarding. Also, the decode and write-back stage are half cycles and are split in one cycle allowing the register to be read then written to in one cycle concurrently. This takes care of one stalled cycle. In the case of forwarding and the load-add example, there would be a single-cycle stall and then the data would be forwarded to the execution unit and the CPU would keep churning.
The add-add instruction would not need to stall at all since the CPU handles the forwarding itself.
For the enhancements that were introduced to the CPU, the CPI has been reduced to 1.2. The execution time is now 2.4. Again, there is more to worry about than just dependencies. What about branches and jumps?
Code
if(something)
{
Do stuff
}
{
Do stuff
}
This if statement above is a typical example of a branch. Other examples include do while loops, for loops, while loops and any type of goto or jump statement. The last two are known as unconditional branches since they always branch. As you can tell, there are many branches in a type program.
Now we have to see how these instructions are being feed into the CPU to understand why branches are a problem. In a typical RISC system, the instruction and data memory are kept separate so there is no structural hazard (In the IF or MEM stage). The instructions are then feed into the CPU in serial order... For example:
Code
1. LOAD
2. STORE
3. ADD
4. ADD
5. BRANCH
6. LOAD
2. STORE
3. ADD
4. ADD
5. BRANCH
6. LOAD
Each instruction begins executing as soon as it can. This means that instructions 1 - 5 will start executing immediately. Instruction 6 must wait until the branch is resolved before it can execute. Let's take a more specific example:
Code
.
LOAD R1,0xFA45
BNEZ R1,jump (branch if not zero)
ADD R1,R3,R5
jump: STORE R1,0x67FE
LOAD R1,0xFA45
BNEZ R1,jump (branch if not zero)
ADD R1,R3,R5
jump: STORE R1,0x67FE
In the above example, the add instruction cannot begin executing until the branch has been resolved. If the CPU were to start executing the add instruction and the branch was taken, the store instruction would be storing the wrong result! It is for this reason that the CPU must stall until the branch can be resolved. After the branch is resolved and the program counter is updated, the CPU will resume as normal. The CPU has no prediction for branches and must effectively flush the pipeline. In this case, the CPU can resolve the branch at the end of the ID stage and update the program counter as well. In this case, there are two stalls for each branch.
Now that we added the problem of branches to the equation, the CPI of the CPU is now 1.4. This means that the execution time of our standard benchmark is now at 2.8 seconds. What can be done to improve this? Predict which way a branch will be taken.
If the CPU predicts that all branches will not be taken, then it can go ahead and start executing the instruction just after the branch without worrying what the branch is. Once the CPU resolves the branch, it can either flush the pipe, or continue to execute the instruction. We are no worse off using this prediction and if branches are not taken, we are better off. I have grossly oversimplified this, but this is how it works.
Now the CPI of our CPU is at 1.3 and the benchmark finishes in 2.6 seconds. For the purpose of this article, this is the best this CPU can hope to achieve.
Conclusion:
Let's compare what we have seen. The single-cycle CPU finishes the benchmark in 5 seconds and is running at 200MHz. The multi-cycle CPU finishes the same benchmark in 2.6 seconds and is running at 500MHz, 2.5x faster in clock speed, but only about 1.92x faster in actual execution time. The modern CPUs all follow this trend and the Pentium 4 line is a great example of this. Intel has increased the pipeline deeper and deeper to increase clockspeeds, but the performance has not increased at the same rate as clockspeed. AMD focuses on doing more per clock (IPC) which is why their pipeline is shorter, but the CPU can accomplish more in one clock cycle. Check back in a week or so for more on CPUs including super scalars and a starter on how cache works.
The diagrams presented in this article come from lecture slides for my class which you can find here: http://guinness.cs.stevens-tech.edu/~arz/ The textbook that was used in the class was Computer Organization and Design: The Hardware/Software Interface, Second Edition.
Thanks for reading and by all means, if you spot any errors in this let me know. You can also discuss this in the forums: »http://www.aseforums.com/.